 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Numbers Speak: Aligning Textual Numerals and Visual Instances in Text-to-Video Diffusion Models
Apr 09, 2026Text-to-video diffusion models have enabled open-ended video synthesis, but often struggle with generating the correct number of objects specified in a prompt. We introduce NUMINA , a training-free identify-then-guide framework for improved numerical alignment. NUMINA identifies prompt-layout inconsistencies by selecting discriminative self- and cross-attention heads to derive a countable latent layout. It then refines this layout conservatively and modulates cross-attention to guide regeneration. On the introduced CountBench, NUMINA improves counting accuracy by up to 7.4% on Wan2.1-1.3B, and by 4.9% and 5.5% on 5B and 14B models, respectively. Furthermore, CLIP alignment is improved while maintaining temporal consistency. These results demonstrate that structural guidance complements seed search and prompt enhancement, offering a practical path toward count-accurate text-to-video diffusion. The code is available at https://github.com/H-EmbodVis/NUMINA.
Mitigating Hallucination on Hallucination in RAG via Ensemble Voting
Mar 28, 2026Retrieval-Augmented Generation (RAG) aims to reduce hallucinations in Large Language Models (LLMs) by integrating external knowledge. However, RAG introduces a critical challenge: hallucination on hallucination," where flawed retrieval results mislead the generation model, leading to compounded hallucinations. To address this issue, we propose VOTE-RAG, a novel, training-free framework with a two-stage structure and efficient, parallelizable voting mechanisms. VOTE-RAG includes: (1) Retrieval Voting, where multiple agents generate diverse queries in parallel and aggregate all retrieved documents; (2) Response Voting, where multiple agents independently generate answers based on the aggregated documents, with the final output determined by majority vote. We conduct comparative experiments on six benchmark datasets. Our results show that VOTE-RAG achieves performance comparable to or surpassing more complex frameworks. Additionally, VOTE-RAG features a simpler architecture, is fully parallelizable, and avoids the problem drift" risk. Our work demonstrates that simple, reliable ensemble voting is a superior and more efficient method for mitigating RAG hallucinations.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022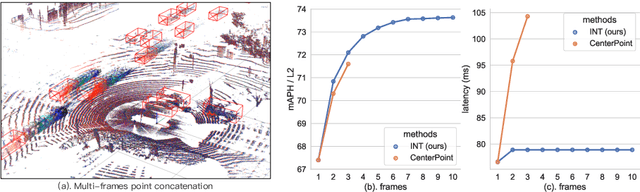
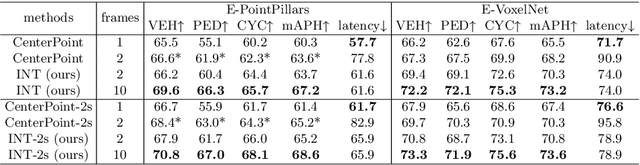
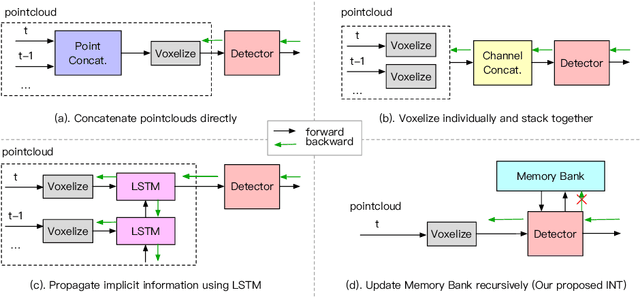
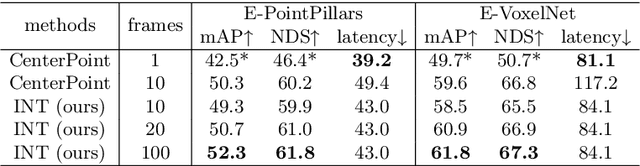
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.